日常工作中经常需要确定各个指标的权重,利用熵值法确定权重属于客观赋权法,从数据出发,避免过强的主观性,但是也同时带来了一些问题。在某个论坛的帖子中,作者提出了这样的一个问题:“熵值法用于确定权重是否合适?什么场合下熵值法是不适用的?”
下面我们就以作者提出的例子利用熵值法进行权重的求解(原贴的求解感觉存在问题),一方面可以学习一下熵值法确定权重的步骤,一方面也体会下熵值法的优缺点。
author: @Huji
熵值法的原理
什么是信息熵
熵是热力学的一个物理概念,是体系混乱度(或无序度)的量度。熵越大说明系统越混乱,携带的信息越少,熵越小说明系统越有序,携带的信息越多。
信息熵则借鉴了热力学中熵的概念 (注意:信息熵的符号与热力学熵应该是相反的[1]),用于描述平均而言事件信息量大小。所以数学上,信息熵其实是事件所包含的信息量的期望[2]。
在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。
根据上面期望的定义,我们可以设想信息熵的公式大概是这样的一个格式
$信息熵=\sum 每种可能事件的概率 * 每种可能事件包含的信息量$
例如预测小明的考试成绩,假如只有4道大题,每道只能得0分或者满分,那么小明成绩可能的事件共有5种:0,25,50,75,100
我们可以假设每种可能的事件发生的概率如下:
| 成绩 | 0分 | 25分 | 50分 | 75分 | 100分 |
|---|---|---|---|---|---|
| 概率 | 1/8 | 1/8 | 1/4 | 1/4 | 1/4 |
这样一来上面的每种可能的事件的概率我们就知道了,那么剩下的就是计算每种可能事件包含的信息量。
那么每种可能事件包含的信息量跟什么有关呢?
答案是跟这一事件的不确定性有关,即与事件发生的概率有关,概率越大,信息量越小。试想,如果上面的概率修改一下,令小明得100分的概率是1,那么你预测小明会考100分这句话就没有信息量了,因为不管怎么样他肯定都会是100分。
因此每种可能事件包含的信息量的计算采用不确定性函数$f$:
$f = log(1/P) = -log P$
采用这个函数,一方面保证了信息量是概率P的单调递降函数;另一方面保证了两个独立事件所产生的不确定性应等于各自不确定性之和,即可加性。
综上,带入到我们一开始假设的公式中,可以得到信息熵的数学表达式如下:
$H(U) = -\sum_{i=1}^{n} P_i logP_i$
这里$H$是熵,$U$可以理解为所有可能事件的集合,有n种取值:$U_1,…,U_i,…,U_n$,对应概率为:$P_1,…,P_i,…,P_n$,对数的底一般取2。
熵值法
根据信息熵的定义,对于某项指标,我们可以用熵值来判断某个指标的离散程度,其熵值越小,指标的离散程度越大,该指标对综合评价的影响(即权重)越大。如果某项指标的值全部相等,那么该指标在综合评价中不起作用。
熵值法的计算步骤
问题描述
作者提出的是这样一个问题
题目:这群学生中“最聪明/最优秀”的学生是谁?
学生 数学 体育 学生5 100 90 学生3 97 89 学生13 88 98 学生7 77 100 学生2 80 96 学生12 98 76 学生9 99 56 学生14 88 56 学生6 90 43 学生11 89 32 学生8 88 32 学生4 90 24 学生15 88 21 学生16 99 1 学生1 89 11 学生10 89 2
计算步骤
注意:相关xlsx文件可以在此处【下载】
- 确定指标体系
首先需要确定评价的指标体系,例如下图是网站经营评价的两级指标体系。
 在我们的例子中,评价指标只有两个:数学和体育的成绩。
在我们的例子中,评价指标只有两个:数学和体育的成绩。 - 清洗指标极值 即剔除各指标中极大或者极小的值,一般用比较合理的上下线替换这些极值,目的是减少极值数据对该指标的熵的影响。 原则:剔除占样本总数不到1-2%但指标值贡献率超过20-30%以上的极值样本。 我们这里样本本来也不多,也没有贡献率特别大的,所以没有做处理。
- 归一化指标处理 将各个指标同度量化,即将指标的实际值转化为不受量纲影响的指标评价值。常用的方法有:
临界值法: 如果原始的第$i$个人的第$j$个指标是$x_{ij}$,那么归一化后是$x_{ij}’$。
$x_{ij}’ = \frac{x_{ij}-\min x_j}{\max x_j - \min x_j}$, $x_{ij}’ = \frac{\max x_j-x_{ij}}{\max x_j - \min x_j}$
若指标是正向的选第一个公式; 若指标是负向的选第二个公式。
$\min x_j$是第$j$个指标的最小值,类似地,$\max x_j$是第$j$个指标的最大值。
Z-score法: $x_{ij}’ = \frac{x_{ij}-\bar{x_j}}{S}$
这里我们采用第一种临界值法,得到结果如下图
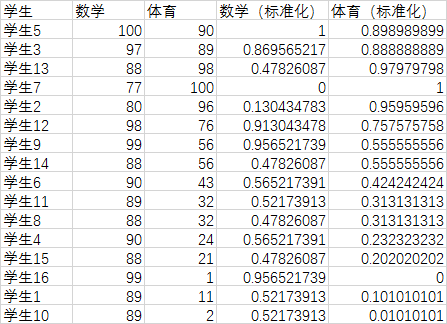
- 计算指标熵和权
-
计算指标熵要先计算第$i$个人的第$j$个指标值的比重 $y_{ij} = \frac{x_{ij}’}{\sum_{i=1}^m {x_{ij}’}}$
-
计算第j项指标的信息熵的公式为 $e_j = -K\sum_{i=1}^m y_{ij} \ln y_{ij}$ (式中$K$为常数,$K=\frac{1}{\ln m}$,我觉得乘以这个主要是为了使得$e_j$小于等于1,这样后面求得的权重才是正数)
-
某项指标的信息效用价值取决于该指标的信息熵$e_j$与1之间的差值,它的值直接影响权重的大小,信息效用值越大,对评价的重要性就越大,权重也就越大。 $d_j = 1 - e_j$
-
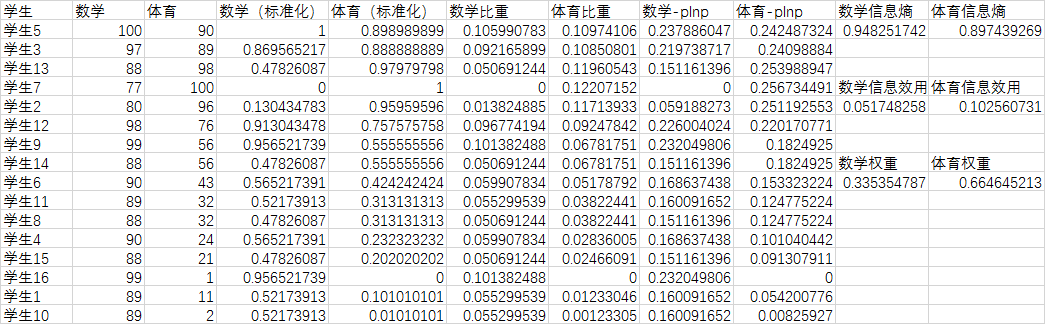
第$j$项指标的权重为$w_j = \frac{d_j}{\sum_j d_j}$
结果如下
- 指标加权计算得分
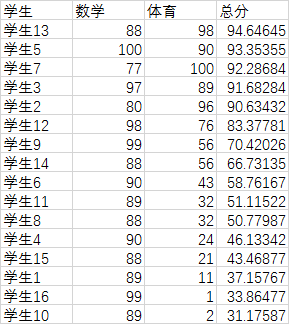
最后一步就是利用加权求和公式计算样本的评价值了 $U = \sum_j 100* y_{ij}w_j$
$U$为综合评价值,$w_j$为第j个指标的权重。
计算出的总分从高到低排序如下图所示:
熵值法的优缺点及适用范围
优点
- 熵值法能深刻反映出指标的区分能力,进而确定权重
- 是一种客观赋权法,有理论依据,相对主观赋权具有较高的可信度和精确度
- 算法简单,实践起来比较方便,不需要借助其他分析软件
缺点
- 智能程度不够高。和多元回归和主成分等统计方法不同,它不能考虑指标与指标之间横向的影响(如:相关性)
- 若无业务经验的指导,权重可能失真
- 对样本的依赖性比较大,随着建模样本变化,权重会有一定的波动
适用范围
结合上面的实例,我们看到:体育成绩离散程度更大,导致其最后权重也更大,但是从通常评判的角度看,聪明程度往往与数学成绩关系更为密切。这就说明单单使用熵值法权重失真是经常发生的,要结合一定专家打分法才能发挥熵值法的优势,像确定指标体系中的示意图那样,构建两级评价体系,上层可能需要结合专家经验来构建,而底层的指标分的比较细,权重比较难确定,这种情况下采用熵值法比较合适。
另外,确定权重前需要确定指标对目标得分的影响方向,对非线性的指标要进行预处理或者剔除。还要注意处理好极值。