这几天心血来潮在Github上建了个博客,纠结了半天才倒腾好,希望以后自己能多总结下学的知识,先从建立博客开始咯~
第一章 Spark简介
author: @Huji
1.1 Spark的技术背景
大多数现有的集群计算系统都是基于非循环的数据流模型。
-
非循环的数据流模型: 从稳定的物理存储(分布式文件系统)中加载记录,记录被传入由一组确定性操作构成的DAG(Directed Acyclic Graph,有向无环图),然后写回稳定存储。
-
数据流模型的特点: 自动容错、位置感知性调度和可伸缩性
-
数据流模型不适合的场景:
- 迭代算法
- 交互式数据挖掘工具
Spark实现了一种分布式的内存抽象,称为弹性分布式数据集(Resilient Distributed Dataset,RDD)。RDD允许用户在执行多个查询时显示地将工作缓存在内在中,后续的查询能够重用工作集。
1.2 Spark的优点
- 速度:和MapReduce相比,基于内存的运算快100倍以上,基于硬盘的运算快10倍以上。
- 易用:支持Java,Python和Scala的API,用户可以快速构建不同应用
- 通用性:可以用于批处理、交互式查询、实时流处理、机器学习和图计算
- 可融合性:可以和其他开源产品进行融合,可以使用Hadoop的YARN和Apache Mesos作为资源管理和调度器,并且可以支持所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等,不需要做数据迁移。
1.3 Spark架构综述
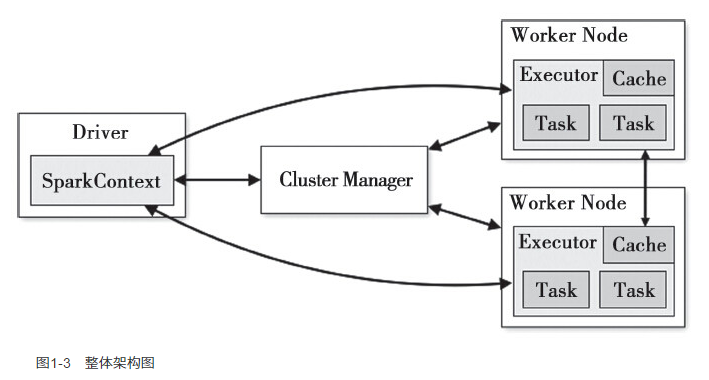 用户程序提交到最终计算执行的步骤:
用户程序提交到最终计算执行的步骤:
- 用户创建的SparkContext实例会连接到Cluster Manager,根据用户设置的CPU和内存信息来分配计算资源,启动Executor
- Driver将程序划分为不同执行阶段,创建Task,向Executor发送Task
- Executor接收到Task后,准备好运行环境,执行Task,并且向Driver汇报Task的运行状态
- Driver根据收到的信息处理不同的状态更新。Task又分为Shuffle Map Task和Result Task
- Driver不断调用Task直到所有Task都正确执行或超过执行次数限制时停止
1.4 核心组件介绍
- Spark Streaming: 将流式计算分解成一系列短小的批处理作业
- MLlib:可以做一些分类,回归,聚类,协同过滤,降维等
- Spark SQL:不管数据源的来源如何,用户都能够通过Spark支持的所有语言来操作这些数据。
- GraphX:关于图和图并行计算的API
1.5 Spark的整体代码结构规模
Spark Core是Spark的核心,上面提到的核心组件都是基于Spark Core的实现和衍生。
Tips on data analysis by python
利用python进行数据分析时的一些小tips,有的是python自带的数据结构,还有很多是针对pandas当中的dataframe和series,因为是零零碎碎整理的 ,比较发散,平时想到了就加进来,所以没太多逻辑哈。